Keeping track of deep learning progress with the huggingface_hub library
Programmatically exploring the latest and greatest models with Python
Being the well-informed person you are, you know about large language models (LLM) and the Transformer architecture, and a bit about the attention mechanism which, as the paper title goes, is “all you need”. But do you know much about the cutting-edge architectures released in the last few months and their adoption? How would you even quantitatively evaluate an LLM? And by the way, did you know that the most downloaded model on Huggingface was an audio classification model? Things are moving so fast, who could blame you for a few information gaps? And still, if you know a bit of Python, you can follow along this story and enjoy some up-to-the-minute data-driven information on the latest deep learning models, using the huggingface_hub package.

Installation
We will use the huggingface_hub and (for convenience) the datasets Python packages, which you can install by running pip install huggingface_hub datasets, or as a byproduct of installing the transformers library.
The Open LLM Leaderboard dataset
As large language models (LLM) are the focus of so much attention, let us start with the Open LLM Leaderboard. Hosted on Huggingface, this leaderboard summarizes the performance of open-source large language models on a set of well-defined benchmarks and represents a welcome source of transparency and reproducibility in this fast-paced domain.
Its results happen to be saved in a dataset which is itself available on the Hugginface Hub, and you can retrieve with a simple call of the load_dataset function, and convert in a Pandas dataframe in a few lines:
import pandas as pd
from datasets import load_dataset
leaderboard_dataset = load_dataset("open-llm-leaderboard/contents")
leaderboard_data = leaderboard_dataset["train"].to_pandas().set_index("eval_name")
for date_column in ["Upload To Hub Date", "Submission Date"]:
leaderboard_data[date_column] = pd.to_datetime(leaderboard_data[date_column])The following scatter plot shows the average score of the 100 highest-rated models against the date of their upload to the Huggingface Hub, with color indicating their architecture type. You will note the remarkable rise of the Qwen2 architecture, developed at Alibaba Cloud, which seems poised to overtake Meta’s LLaMAs.

Feel free to apply your deep data analysis skills to the data. But please note that this is still a very new version of the open LLM leaderboard. And it is worth digging a bit deeper into the benchmarks and their metrics before drawing excessive conclusions about the rate of LLM performance increase.
The most popular models overall
With all the talk about them, are large language models actually the most popular models? Let us get a list of models on the Huggingface Hub sorted by number of downloads or likes. This is as easy as calling the list_models method on an instance of the HfApi class:
from huggingface_hub import HfApi
api = HfApi()
model_generator = api.list_models(sort="downloads", limit=30)
attributes_to_extract = ["downloads", "likes", "created_at", "tags", "pipeline_tag"]
model_dicts = {}
for model in model_generator:
model_dicts[model.id] = {attr: getattr(model, attr) for attr in attributes_to_extract}
popular_models = pd.DataFrame(model_dicts).T
popular_models.index.name = "model_name"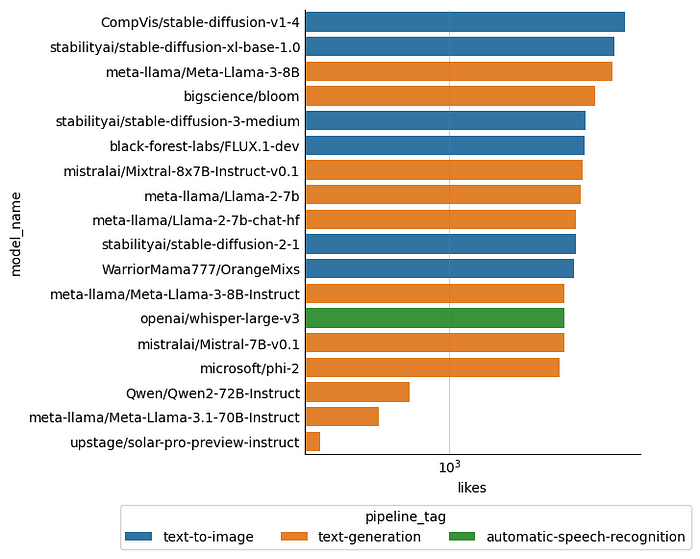
Models in the Open LLM Leaderboard (the bottom three models in the above plot) are far from being the most liked ones. Smaller text generation models with 7 or 8 billion parameters seem more broadly popular. Overall, text-to-image models — mostly stable diffusion models — are even more popular.
Likes and claps are nice, but the number of downloads may be a more solid measure of popularity. Note that the numbers returned by huggingface_hub and shown here correspond to downloads of the model over the last 30 days. As you can observe in the following plot, the most downloaded Huggingface model overall is an audio classification model fine-tuned on the AudioSet dataset. Interestingly, this is also a Transformer model: AST stands for Audio Spectrogram Transformer, and it actually works by applying a Vision Transformer (ViT) to a spectrogram (which is an image representation of sound). Also, the number of downloads of this AST model is several hundred times higher than that of the most downloaded LLM from the leaderboard we looked at above, a 70B LLaMA. You may also notice other star models in different categories, including Chronos (a time series Transformer), Vision Transformers for zero-shot image classification and good old BERT for masked language modeling.

Conclusion
This story showed you how to keep an electronic eye on new and interesting deep learning models by using the huggingface_hub Python package, which gives you programmatic access to a lot of information on models and datasets hosted on Huggingface. In particular, running the two snippets provided in the story will allow you to 1) know what the best-performing open large language models are at a given time, and what architecture they are based on and 2) discover the most popular models for a variety of tasks. But so much more is possible, and I hope this story can inspire you to start your own investigations of the Huggingface Hub.
References and further reading
- Look at the actual library documentation on the Huggingface website:
- If you are interested in quantitative explorations of the machine learning landscape, you may also like my story on looking at Git commits in open-source machine learning frameworks:
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io