K-Nearest Neighbors (KNN)
Implementation and evaluation of KNN model in python

Creating a model to make predictions based on fresh data or forecast future occurrences based on unobserved data is the ultimate objective of a machine learning engineer or data scientist.
After completing this tutorial, you will know:
- What is KNN ?
- How to implement KNN in Python
- Evaluation of the model
- How to choose k values
A well-liked machine learning technique K-Nearest Neighbors (KNN) is used for both classification and regression problems. This algorithm, which belongs to the class of instance-based or lazy learning techniques, is straightforward but effective. why this technique is said to be non-parametric if it makes no assumptions about the distribution of the underlying data. In other words, the data are used to determine the model’s structure. It makes sense if you think about it, as most data in the “real world” defies common theoretical presumptions (like those in linear regression models, for instance).

In simple words,
Imagine you’re at a party, and you’re trying to figure out who your new best friend should be. You don’t know much about the people there, but you notice that you tend to get along with people who have similar interests.

So, you decide to use the KNN algorithm for friendship-finding. Here’s how it works:
1. Pick a “K” Value: First, you choose a value for “K.” K is like your social circle size. If you pick K = 3, it means you’ll consider the three closest people to you.
2. Find Your Neighbours: You start by looking at the three people standing closest to you at the party. These are your “nearest neighbours."
3. Vote for Friendship: You ask your nearest neighbours about their interests and hobbies. Let’s say two of them love hiking and one loves video games. Since you’re a nature enthusiast, you decide that the majority of your neighbours are into hiking.
4. Make a New Friend: Based on this vote, you decide to befriend people who love hiking. So, you become friends with the two hiking enthusiasts, and you all plan a hiking trip together.
5. Keep It Social: As the party goes on, you keep reevaluating your friends. If someone new joins your social circle (becomes one of your nearest neighbours), you check their interests and decide if they should be added to your friend group.
6. Partying on Repeat: You keep repeating this process throughout the party, adjusting your friend group as needed based on your nearest neighbours' interests.
That’s KNN in a nutshell! It’s like making friends at a party by looking at the interests of the people closest to you. Just remember, choose your K wisely; if it’s too low, you might end up with weird friends, and if it’s too high, you might miss out on meeting cool people!
Refer below to the link for your reference
Implementation
This is how you can import KNN algo.
from sklearn.neighbors import KNeighborsClassifierHere K = 1
knn = KNeighborsClassifier(n_neighbors=1)Split your data into training and test sets and populate the predicted results.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x_axis, y_axis, test_size=0.33, random_state=42)
knn.fit(X_train,y_train)
pred = knn.predict(X_test)Evaluation
Now here is the exciting part: it’s time for an evaluation of your hard work.
I typically develop a confusion matrix for evaluation, which aids in determining how well our model predicts outcomes and performs cross-validation.
so in this case, I am using K-fold cross-validation
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,pred))
From the confusion matrix, we get results for True positives, False Positives, False Negatives, and True Negatives.
[[46 8]
[14 22]]classification report, give us the consolidated results.
print(classification_report(y_test,pred)) precision recall f1-score support
0 0.77 0.85 0.81 54
1 0.73 0.61 0.67 36
accuracy 0.76 90
macro avg 0.75 0.73 0.74 90
weighted avg 0.75 0.76 0.75 90How can we decide K values?
Now it’s time to find out. Our best friend, I mean K value. So here I am giving k values from 1 to 40.
The cross-validation score will enable us to assess the precision of various k values.
accuracy_rate = []
It Will take some time
for i in the range (1,40):
knn = KNeighborsClassifier(n_neighbors=i)
score=cross_val_score(knn,x_axis,y_axis,cv=10)
accuracy_rate.append(score.mean())Error rate calculations for various k values
error_rate = []
# Will take some time
for i in range(1,40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train,y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))plt.figure(figsize=(10,6))
plt.plot(range(1,40), accuracy_rate, color='blue', linestyle='dashed', marker='o',
markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')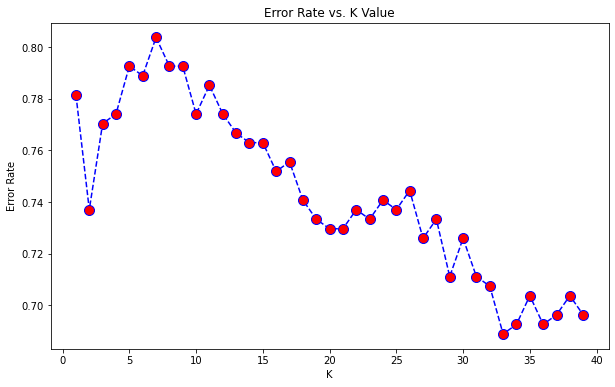
If you liked this blog give it some CLAPS and SHARE it with your friends, stay tuned for more interesting techniques and concepts of Machine Learning.
Github :- https://github.com/shubhamchauda/
In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us on Twitter(X), LinkedIn, YouTube, and Discord.
