How to Build an Auto-Updating Open-Source Dataset Using Kaggle API and GitHub Actions
A guide on building an auto-updating open-source dataset using Kaggle API and GitHub Actions.

In this article, we will see how to take any web scrapper or data fetcher that relies on a data source that updates frequently, trigger it every day using GitHub Actions and update our dataset hosted in Kaggle.
Did you ever come across an interesting data source that you thought might be useful to others but don’t know where to start? Did you ever write a web scraper to fetch and parse data and do a one-time analysis and throw it away? Either way, in this article, I will be helping you to create your first open-source dataset and also how to extend the lifetime of your scrapper and maintain it using open source tools. Open source development has never been this easier. With free compute and storage available for most open source projects, these resources should be utilized effectively. We will be using Kaggle to host our dataset and GitHub Actions for updating it.
Kaggle is an excellent source to host a dataset. It enables the easy discoverability of a dataset along with the ability for anyone to quickly work on your dataset using a kernel. GitHub Actions provide free compute that we will use as a CRON job to trigger the data fetcher to fetch the new data available from our data source and add that back to our dataset.
Data
We will be scrapping PM Modi’s text speeches, available here. The scraper is irrelevant and only shown as an example, the process of automating it is the main focus. If you want to follow along check out the repo here.
We will be extracting the speeches along with metadata like tags and publishing info. New content is added whenever Modi makes a speech and added to the website. We will be setting up a scrapper to check and fetch this data every day.
Kaggle API
After collecting the bulk of the data in the first run and cleaning it, let’s upload it to Kaggle Datasets. We can add documentation and metadata to our dataset including Data set descriptions, column descriptions, and how frequently the datasets will be updated. The dataset will be available under the URL, https://www.kaggle.com/username/dataset-name

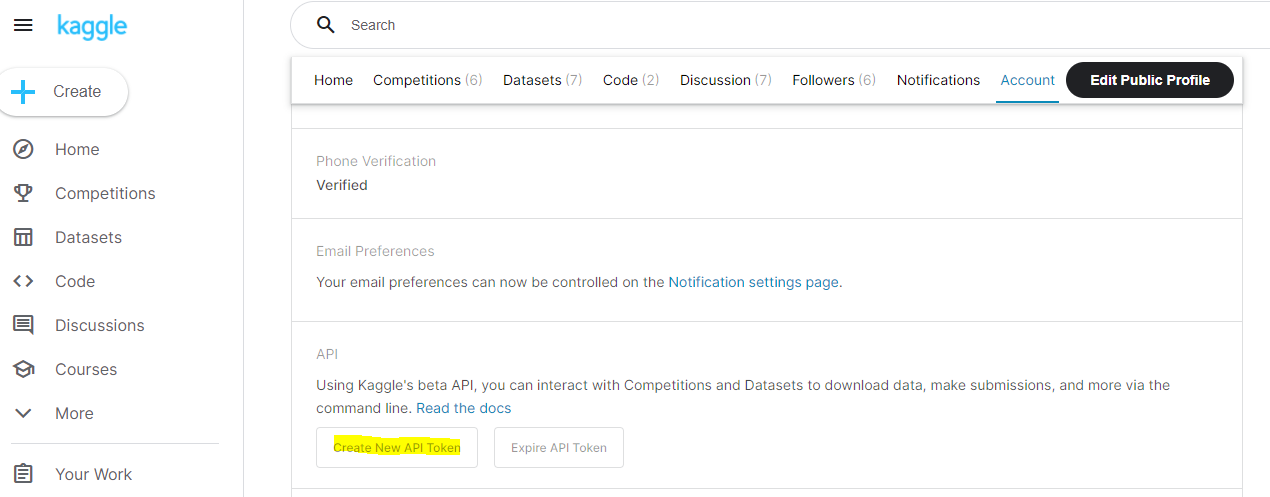
After the initial upload, we will be relying on Kaggle’s python API for automating our delta uploads. Before starting to use the API, we need to create API Token for authentication. Navigate to your Kaggle Account and click on the Create New API Token button, which will download a JSON containing KAGGLE_USERNAME and KAGGLE_PASSWORD.
We will be using the API to do two things,
- Calculate Delta
- Upload Changes
Calculating Delta
In order to update a dataset, we need to calculate a delta. Delta is the new data that has been added to our data source, since the last time we checked. In our example, it is the new speeches that are added to the website. We need our previous state to check if there are any additions to our data source. We can do that by getting the last entry in our Kaggle data source and then scrapping the speeches until we come across the latest entry from our previous run.
The website gets data by making a GET API request to fetch the text speeches as HTML. Bypassing web scrapping and directly making these API requests ourselves, we can parse out the HTML to get the data we need.
Here we loop through pages and articles on each page until we come across the last speech in our previous run. This gives us a list of speeches that have been added since the last run. To get the last data point in our previous run, we can download the Kaggle dataset using the API and then get the first speech title and that is the latest speech that we have now.
Upload Changes
We can now concatenate our new changes with the old changes that we downloaded and upload them back to Kaggle datasets. We will be creating a new version of our dataset in Kaggle. To create a new Kaggle data version, create a folder to store our data and a dataset metadata JSON under the same folder. Let’s create a folder data in the same directory as our scrapper. Now we can export the new data to this folder and then upload it to Kaggle as a new version.
The dataset metadata JSON should be of the following format and will reflect in your new data set version. You can programmatically update your metadata as well on every run.
Automating end-to-end
The last thing anyone wants is an out-of-date data source. It provides additional credibility to a data source knowing that it was updated recently. Most people will build a scrapper, upload the dataset and call it quits. We will go a step further and see how easy it is to set up a workflow to auto-update your dataset and use the scrapper that you already built wisely.
Let’s create a GitHub action by creating a file .github/workflows/speech_scrapper.yml in our repo.
The above GitHub Action is configured to run as a CRON job every day at 8 AM. You can change it to match your data source. You can also run this action manually for testing purposes under actions tab.
The GitHub Action has 7 major steps starting with checking out the latest version of the code base, followed by installing python, installing poetry, setting up the virtual environment, and installing dependencies. The last step is to run the scrapper itself. The environment variables can be either added as repo secrets or as environment secrets(which will require setting the environment attribute).
References:
I am a Data Scientist working in Oil 🛢️ & Gas ⛽. If you like my content, follow me 👍🏽 on LinkedIn, Medium, and GitHub. Subscribe to get an alert whenever I post on Medium.
More content at plainenglish.io. Sign up for our free weekly newsletter. Get exclusive access to writing opportunities and advice in our community Discord.

