101 Guide to PyTorch
Covers all the basics and some common PyTorch Modules

Introduction
PyTorch is an open-source machine learning library for Python which allows maximum flexibility and speed on scientific computing for deep learning.
At its core, PyTorch provides two main features:
- An n-dimensional Tensor, similar to NumPy but can run on GPUs
- Automatic differentiation for building and training neural networks
Tensors in PyTorch
A tensor is an n-dimensional data container which is similar to NumPy’s ndarray. We can use these tensors on a GPU as well (this is not the case with NumPy arrays).
PyTorch supports multiple types of tensors, including:
- Float Tensor: 32-bit float
- Double Tensor: 64-bit float
- Half Tensor: 16-bit float
- Int Tensor: 32-bit int
- Long Tensor: 64-bit int
To Initialize a tensor, we can either assign values directly or set the size of the tensor.
import torch# create a tensor
new_tensor = torch.Tensor([[1, 2], [3, 4]])# create a 3 x 3 tensor with random values
empty_tensor = torch.Tensor(3, 3)
To access or replace elements in a tensor, indexing can be used.
new_tensor[1][1] will return a tensor object that contains the element at position 1, 1.
Slicing can also be used to access every row and column in a tensor.
# elements from every row, first column of a tensor
print(slice_tensor[:, 0])# all elements on the first row
print(slice_tensor[1, :])
x.type(), x.size() can be used to access the tensor information (type/shape of a tensor).
# type of a tensor
print(new_tensor.type())# shape of a tensor
print(new_tensor.shape)
print(new_tensor.size())
Reshaping on dimension of Tensor can be done using view(n,m). This converts the shape of a tensor to the size n x m.
tensor = torch.Tensor([[1, 2], [3, 4]])reshape_tensor.view(1,4) # tensor([[ 1., 2., 3., 4.]])
Basic Tensor Operations
- Transpose:
.t()or.permute(-1, 0)
# regular transpose function
tensor.t()# transpose via permute function
tensor.permute(-1,0)
2. Matrix Product: .mm()
matrix_product = tensor_1.mm(tensor_2)3. Arithmetic operations (+,-,*,/)
#matrix addition
print(torch.add(a,b), '\n')# matrix subtraction
print(torch.sub(a,b), '\n')# matrix multiplication
print(torch.mm(a,b), '\n')# matrix division
print(torch.div(a,b), '\n')
4. Cross Product: a.cross(b) or torch.cross(a, b)
#creating two random 3x3 matrices
tensor_1 = torch.randn(3, 3)
tensor_2 = torch.randn(3, 3) cross_prod = tensor_1.cross(tensor_2)
5. Concatenating Tensors
# concatenating vertically
torch.cat((a,b))We can concatenate the tensors horizontally as well by setting the dim parameter to 1.
# concatenating horizontally
torch.cat((a,b),dim=1)PyTorch — NumPy Bridge
A NumPy ndarray can be converted to a PyTorch tensor and vice versa.
.from_numpy() is used to convert a NumPy ndarray to a PyTorch tensor.
.numpy()is used to convert the tensor back to a NumPy ndarray.
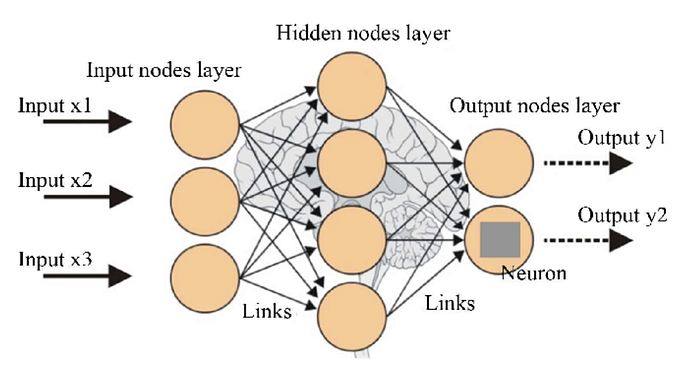
Background on NN for PyTorch Modules
Neural networks (NNs) are a collection of nested functions that are executed on some input data. These functions are defined by parameters (consisting of weights and biases), which in PyTorch are stored in tensors.
Training a NN happens in two steps:
Forward Propagation: The NN makes its best guess about the correct output. It runs the input data through each of its functions to make this guess.
Backward Propagation:The NN adjusts its parameters proportionate to the error in its guess. It does this by traversing backwards from the output, collecting the derivatives of the error with respect to the parameters of the functions (gradients), and optimizing the parameters using gradient descent (Gradient descent is an optimization algorithm used to minimize some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient).
Common PyTorch Modules
- Autograd Module
torch.autograd is PyTorch’s automatic differentiation engine that powers neural network training. It records all the operations that we are performing and replays it backward to compute gradients. This technique helps us to save time on each epoch as we are calculating the gradients on the forward pass itself.
Let’s consider a tensor a with requires_grad=True. This signals to autograd that every operation on the tensor should be tracked.
import torch
a = torch.tensor([1., 2.], requires_grad=True)# performing operations on the tensor
b = a + 5
c = b.mean()
print(b,c)OUTPUT: tensor([6., 7.], grad_fn=<AddBackward0>) tensor(6.5000, grad_fn=<MeanBackward0>)
Now, the derivative of c with respect to a will be ½ and hence the gradient matrix will be 0.50. Let’s verify this using PyTorch:
# back propagating
c.backward() # computing gradients
print(a.grad)OUTPUT: tensor([0.5000, 0.5000])
Autograd as expected, computes the gradients.
2. Optim Module
The Optim module in PyTorch has pre-written codes for most of the optimizers that are required while building a neural network.
# importing the optim module from PyTorch
import optimMost of the commonly used optimizers are supported in PyTorch and hence we do not have to write them from scratch.
3. nn Module
When we are dealing with a complex neural network, this module defines a set of functions, similar to the layers of a neural network, which takes the input from the previous state and produces an output.
import torch.nn as nn
import torch.nn.functional as FThe nn module is one of the most common modules used to train deep neural networks in PyTorch.